Spark Core
# 一、RDD 基础
# 1.1 RDD 概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合,所有的运算以及操作都建立在 RDD 数据结构的基础之上。
RDD 提供了一个抽象的数据模型,不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API(map/reduec/filter/groupBy 等)。
# 1.2 RDD 特征
- 一组 Partition。Partition 是 RDD 的基本组成单位,每个 Partition 都会被一个 Task 处理,Partition 数量决定任务并行度。用户可以在创建 RDD 的时候指定分区数,如果没有指定则会采用默认值。
- 一个计算每个分区的函数。RDD 的计算是以 Partition 为单位的,计算函数会作用到每个分区上。
- RDD 之间的依赖关系。RDD 的每次转换都会生成一个新的 RDD,所以 RDD 之间会形成一个前后依赖关系。在部分分区数据丢失或 Task 执行失败以后可以通过依赖关系重新计算该分区的数据,而不是重新计算所有分区。
- 一个针对 Key-Value 型 RDD 的分区器(可选的)。对于 Key-Value 型的 RDD 会有一个分区器,非 Key-Value 型的 RDD 分区器是 None。Spark 中内置的有 HashPartitioner 和 RangePartitioner。
- 一个列表,存储存取每个 Partition 的优先位置(可选的)。对于一个 HDFS 文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照"移动数据不如移动计算"的理念,Spark 在进行任务调度的时候,会尽可能选择那些存有数据的 worker 节点来进行任务计算。
# 1.3 创建 RDD
在 Spark 中创建 RDD 的创建方式可以分为两种:
- 从并行化本地集合创建;
- 从外部存储创建 RDD。
# 1.3.1 并行化集合创建
示例:
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
val rdd2 = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
2
3
# 1.3.2 外部存储创建
示例:
val rdd = sc.textFile("data.txt")
# 二、RDD 算子
Spark 中的算子分为 Transformation 和 Action 两种。Transformation 会返回一个新的 RDD,但是 Transformation 不会立即触发计算,只是记录 RDD 的转换过程,只有调用 Action 算子才会真正触发计算任务。
提示
RDD 中的所有转换都是 lazy 执行的,也就是说并不会直接计算。只有当发生一个要求返回结果给 Driver 的 Action 动作时,这些转换才会真正运行。之所以使用惰性求值/延迟执行,是因为这样可以在 Action 时对 RDD 操作形成 DAG 有向无环图进行 Stage 的划分和并行优化,这种设计让 Spark 更加有效率地运行。
# 2.1 Transformation
- map(func):返回一个新的 RDD,该 RDD 由每一个输入元素经过 func 函数转换后组成。
- mapPartitions(func):类似于 map,但独立地在 RDD 的每一个分片上运行,因此在类型为 T 的 RDD 上运行时,func 的函数类型必须是 Iterator[T] => Iterator[U]。假设有 N 个元素,有 M 个分区,那么 map 的函数的将被调用 N 次,而 mapPartitions 被调用 M 次,一个函数一次处理所有分区。
map 和 mapPartition 的区别:
map 每次处理一条数据,mapPartition 每次处理一个分区的数据,这个分区的数据处理完后,原 RDD 中分区的数据才能释放,可能导致 OOM。如果内存足够大可以使用 mapPartition 提高处理效率。
- mapPartitionsWithIndex(func):类似于 mapPartitions,但 func 带有一个整数参数表示分片的索引值,因此在类型为 T 的 RDD 上运行时,func 的函数类型必须是(Int, Interator[T]) => Iterator[U]。
- flatMap(func):类似于 map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以 func 应该返回一个序列,而不是单一元素)。
- glom:将每一个分区形成一个数组,形成新的 RDD 类型时 RDD[Array[T]]。
- groupBy(func):分组,按照传入函数的返回值进行分组。将相同的 key 对应的值放入一个迭代器。
- filter(func):过滤。返回一个新的 RDD,该 RDD 由经过 func 函数计算后返回值为 true 的输入元素组成。
- sample(withReplacement, fraction, seed) :以指定的随机种子随机抽样出数量为 fraction 的数据,withReplacement 表示是抽出的数据是否放回,true 为有放回的抽样,false 为无放回的抽样,seed 用于指定随机数生成器种子。
- distinct([numTasks])):对源 RDD 进行去重后返回一个新的 RDD。默认情况下,只有 8 个并行任务来操作,但是可以传入一个可选的 numTasks 参数改变它。
- coalesce(numPartitions):缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。
- repartition(numPartitions):根据分区数,重新通过网络随机洗牌所有数据。
coalesce 和 repartition 的区别:
- coalesce 重新分区,可以选择是否进行 shuffle 过程。由参数 shuffle: Boolean = false/true 决定。
- repartition 实际上是调用了 coalesce,一定会产生 shuffle。源码如下:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
2
3
- sortBy(func,[ascending], [numTasks]):使用 func 先对数据进行处理,按照处理后的数据比较结果排序,默认为正序。
- pipe(command, [envVars]):管道,针对每个分区,都执行一个 shell 脚本,返回输出的 RDD。
- union(otherDataset):对源 RDD 和参数 RDD 求并集后返回一个新的 RDD。
- subtract (otherDataset):计算差的一种函数,去除两个 RDD 中相同的元素,不同的 RDD 将保留下来。
- intersection(otherDataset):对源 RDD 和参数 RDD 求交集后返回一个新的 RDD。
- cartesian(otherDataset):计算笛卡尔积。
- zip(otherDataset):将两个 RDD 组合成 Key/Value 形式的 RDD,这里默认两个 RDD 的 partition 数量以及元素数量都相同,否则会抛出异常。
- partitionBy:对 pairRDD 进行分区操作,如果原有的 partionRDD 和现有的 partionRDD 是一致的话就不进行分区, 否则会生成 ShuffleRDD,即会产生 shuffle 过程。
- groupByKey:groupByKey 也是对每个 key 进行操作,但只生成一个 sequence。
- reduceByKey(func, [numTasks]):在一个(K,V)的 RDD 上调用,返回一个(K,V)的 RDD,使用指定的 reduce 函数,将相同 key 的值聚合到一起,reduce 任务的个数可以通过第二个可选的参数来设置。
reduceByKey 和 groupByKey 的区别:
- reduceByKey 在 shuffle 之前有预聚合操作;
- groupByKey 直接进行 shuffle。
- aggregateByKey:在 kv 对的 RDD 中,,按 key 将 value 进行分组合并,合并时,将每个 value 和初始值作为 seq 函数的参数,进行计算,返回的结果作为一个新的 kv 对,然后再将结果按照 key 进行合并,最后将每个分组的 value 传递给 combine 函数进行计算(先将前两个 value 进行计算,将返回结果和下一个 value 传给 combine 函数,以此类推),将 key 与计算结果作为一个新的 kv 对输出。
- foldByKey:aggregateByKey 的简化操作,参数 seqop 和 combop 相同
- combineByKey:对相同 K,把 V 合并成一个集合。
- sortByKey([ascending], [numTasks]):在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口,返回一个按照 key 进行排序的(K,V)的 RDD。
- mapValues:针对于(K,V)形式的类型只对 V 进行操作。
- join(otherDataset, [numTasks]):在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素对在一起的(K,(V,W))的 RDD。
- cogroup(otherDataset, [numTasks]):在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable< V>,Iterable< W>))类型的 RDD。
# 2.2 Action
- reduce(func):通过 func 函数聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据。
- collect():在驱动程序中,以数组的形式返回数据集的所有元素。
- count():返回 RDD 中元素的个数。
- first():返回 RDD 中的第一个元素。
- take(n):返回一个由 RDD 的前 n 个元素组成的数组。
- takeOrdered(n):返回该 RDD 排序后的前 n 个元素组成的数组。
- aggregate:将每个分区里面的元素通过 seqOp 和初始值进行聚合,然后用 combine 函数将每个分区的结果和初始值(zeroValue)进行 combine 操作。这个函数最终返回的类型不需要和 RDD 中元素类型一致。
- fold:aggregate 的简化操作,参数 seqop 和 combop 一样。
- saveAsTextFile(path):将数据集的元素以 textfile 的形式保存到 HDFS 文件系统或者其他支持的文件系统,对于每个元素,Spark 将会调用 toString 方法,将它装换为文件中的文本。
- saveAsSequenceFile(path):将数据集中的元素以 Hadoop sequencefile 的格式保存到指定的目录下,可以使 HDFS 或者其他 Hadoop 支持的文件系统。
- saveAsObjectFile(path):用于将 RDD 中的元素序列化成对象,存储到文件中。
- countByKey():针对(K,V)类型的 RDD,返回一个(K,Int)的 map,表示每一个 key 对应的元素个数。
- foreach(func):在数据集的每一个元素上,运行函数 func 进行更新。
# 三、RDD 依赖
RDD 的容错机制是通过将 RDD 间转移操作构建成有向无环图来实现的。从抽象的角度看,RDD 间存在着血统继承关系,其本质上是 RDD 之间的依赖(Dependency)关系。RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(shuffle dependency)。
# 3.1 窄依赖
窄依赖中每个父 RDD 的 Partition 最多被一个子 RDD 的一个 Partition 使用。
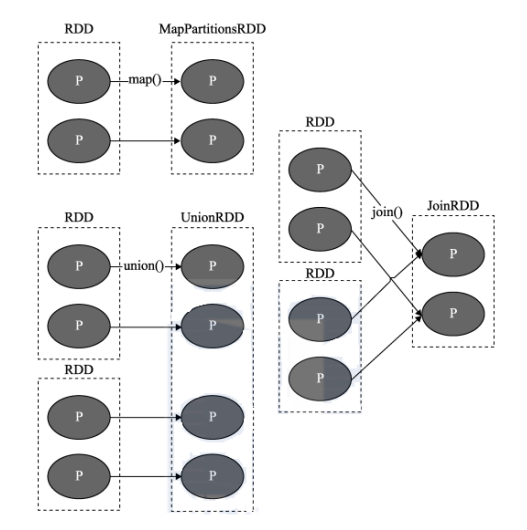
# 3.2 宽依赖
宽依赖中多个子 RDD 的 Partition 会依赖同一个父 RDD 对的 Partition,会引起 Shuffle。
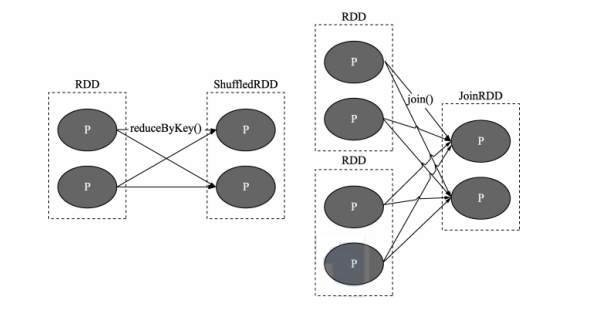
# 3.3 DAG
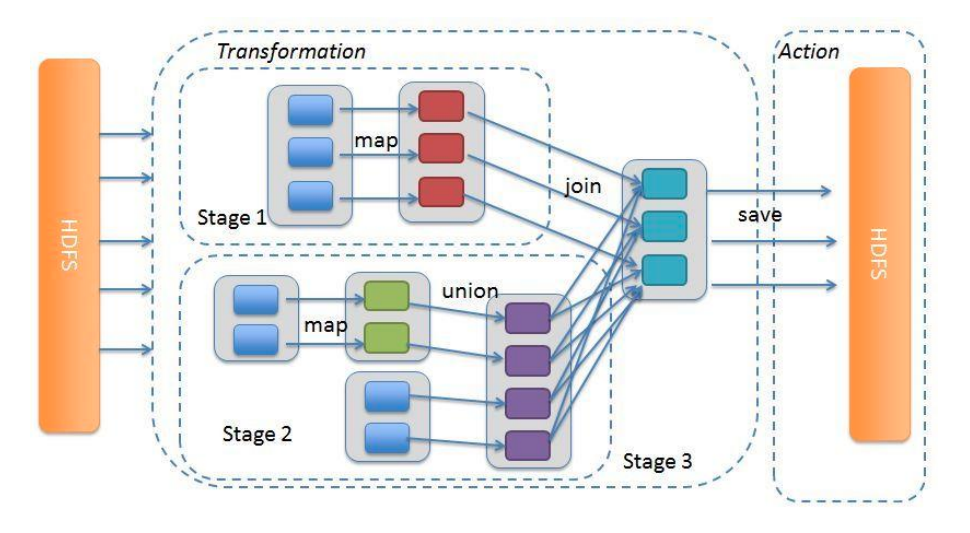
由于计算过程很多时候会有先后顺序,受制于某些任务必须比另一些任务较早执行的限制,必须对任务进行排队,形成一个队列的任务集合,这个队列的任务集合就是 DAG(有向无环图)。
根据 RDD 之间的宽窄依赖关系可以将 DAG 划分成不同的 Stage,对于窄依赖,partition 的转换处理在 Stage 中完成计算。对于宽依赖,由于有 Shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。Stage 是由一组并行的 Task 组成(由于同一个 Stage 内部的 RDD 之间都是窄依赖,窄依赖的 RDD 分区之间是一对一的关系,所以是可以并行的)。
# 四、RDD 持久化
Spark RDD 持久化可以分为 RDD 缓存和 RDD CheckPoint 两种。
# 4.1 缓存
如果在应用程序中多次使用同一个 RDD,可以将该 RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其它地方用到该 RDD 的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
# 4.1.1 缓存级别
Spark 中关于缓存级别的定义如下:
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
2
3
4
5
6
7
8
9
10
11
12
NONE表示不缓存;DISK_ONLY表示缓存到磁盘中;MEMORY_ONLY表示缓存到 Executor 内存中;MEMORY_AND_DISK表示缓存到 Executor 内存中,如果内存不够则缓存到磁盘;OFF_HEAP表示缓存到系统内存中。
其中_2后缀表示缓存 2 份副本,_SER后缀表示是序列化存储。
# 4.1.2 缓存方法
RDD 通过 persist() 方法或 cache() 方法可以将前面的计算结果缓存。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
2
3
4
5
6
7
8
9
从源码中可以看到,cache()调用的是persist()方法,缓存级别为MEMORY_ONLY。
注意
如果数据类型是 RDD,cache()缓存级别为MEMORY_ONLY,但如果数据类型是 DataFrame 或 DataSet,则cache()缓存级别为MEMORY_AND_DISK。源码如下:
/**
* Persist this Dataset with the default storage level (`MEMORY_AND_DISK`).
*
* @group basic
* @since 1.6.0
*/
def persist(): this.type = {
sparkSession.sharedState.cacheManager.cacheQuery(this)
this
}
/**
* Persist this Dataset with the default storage level (`MEMORY_AND_DISK`).
*
* @group basic
* @since 1.6.0
*/
def cache(): this.type = persist()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 4.1.3 释放缓存
调用unpersist()方法释放缓存。
# 4.2 CheckPoint
RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
Checkpoint 的产生就是为了更加可靠的数据持久化,在 Checkpoint 的时候一般把数据放在在 HDFS 上,这就天然的借助了 HDFS 天生的高容错、高可靠来实现数据最大程度上的安全,实现了 RDD 的容错和高可用。
为当前 RDD 设置 Checkpoint。该函数将会创建一个二进制的文件,并存储到 Checkpoint 目录中,该目录是用 SparkContext.setCheckpointDir()设置的。在 Checkpoint 的过程中,该 RDD 的所有依赖于父 RDD 中的信息将全部被移除。对 RDD 进行 Checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
在 Checkpoint 的时候强烈建议先进行 Cache,并且当你 Checkpoint 执行成功了,那么前面所有的 RDD 依赖都会被销毁:
/**
* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
* directory set with `SparkContext#setCheckpointDir` and all references to its parent
* RDDs will be removed. This function must be called before any job has been
* executed on this RDD. It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
def checkpoint(): Unit = RDDCheckpointData.synchronized {
// NOTE: we use a global lock here due to complexities downstream with ensuring
// children RDD partitions point to the correct parent partitions. In the future
// we should revisit this consideration.
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
使用示例:
sc.setCheckpointDir("hdfs://localhost:9000/test")
rdd.checkpoint()
2
3
缓存和 Checkpoint 的区别:
- 存储位置不同
- 缓存只能保存在本地的磁盘和内存中(或者堆外内存);
- Checkpoint 可以保存数据到 HDFS 这类可靠的存储上。
- 生命周期不同
- 缓存的 RDD 会在程序结束后会被清除或者手动调用 unpersist 方法;
- Checkpoint 的 RDD 在程序结束后依然存在,不会被删除。
- 血缘管理不同
- 缓存不会丢失 RDD 的血缘关系,因为内存和磁盘都不可靠;
- Checkpoint 会斩断依赖链,因为 Checkpoint 会把结果保存在 HDFS 这类存储中,更加的安全可靠,一般不需要回溯依赖链。
# 五、共享变量
在默认情况下,当 Spark 在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark 提供了两种类型的变量:广播变量(Broadcast Variables)和累加器(Accumulators)。
# 5.1 广播变量
广播变量允许开发人员在每个节点缓存只读变量,而不是在 Task 之间传递这些变量。使用广播变量能够高效地在集群每个节点创建大数据集的副本。同时 Spark 还使用高效的广播算法分发这些变量,从而减少通信的开销。
使用示例:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
2
3
4
5
# 5.2 累加器
Spark 提供的 Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator 只提供了累加的功能,即提供了多个 Task 对一个变量并行操作的功能。但是 Task 只能对 Accumulator 进行累加操作,不能读取 Accumulator 的值,只有 Driver 程序可以读取 Accumulator 的值。创建的 Accumulator 变量的值能够在 Spark Web UI 中查看,在创建时应该尽量为其命名。
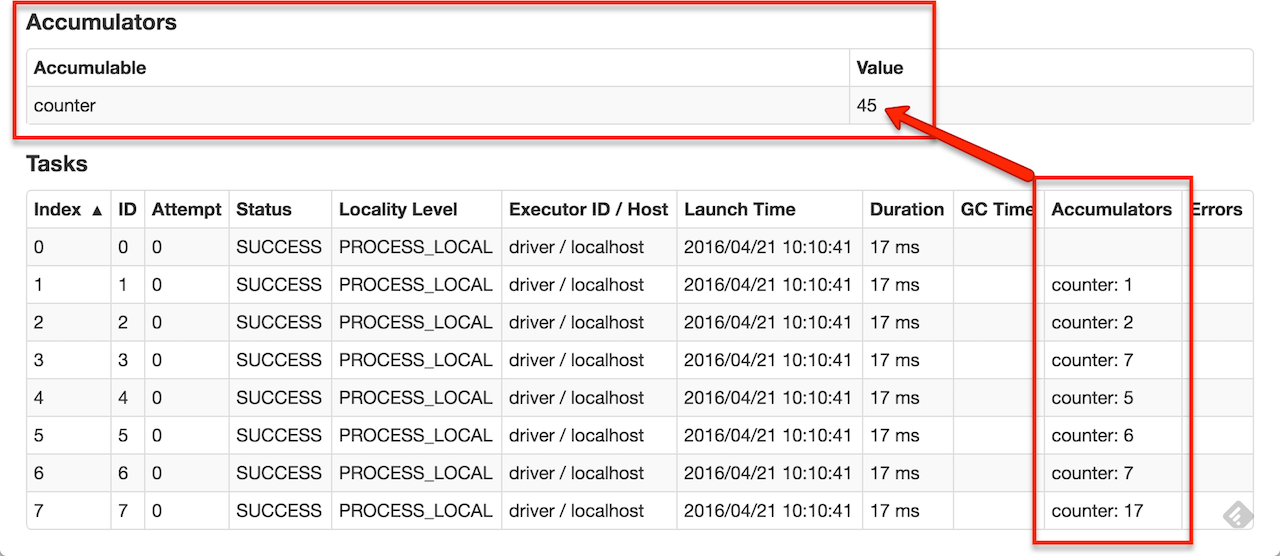
Spark 内置了三种类型的 Accumulator,分别是:
- LongAccumulator:累加整数
- DoubleAccumulator:累加浮点数
- CollectionAccumulator:累加集合元素
当内置的 Accumulator 无法满足要求时,可以继承org.apache.spark.util.AccumulatorV2实现自定义的累加器。
# 5.2.1 内置累加器
内置累加器使用示例:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Long = 10
2
3
4
5
6
7
8
9
# 5.2.2 自定义累加器
步骤:
- 继承
org.apache.spark.util.AccumulatorV2; - 实现
reset()和add()方法; - 在 SparkContext 注册自定义累加器。
官方示例:
class VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] {
private val myVector: MyVector = MyVector.createZeroVector
def reset(): Unit = {
myVector.reset()
}
def add(v: MyVector): Unit = {
myVector.add(v)
}
...
}
val myVectorAcc = new VectorAccumulatorV2
sc.register(myVectorAcc, "MyVectorAcc1")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 六、分区器
只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区器为 None。
可以通过 RDD 的partitioner属性获取分区器,Spark 内置的有两种:HashPartitioner和RangePartitioner。如果内置的分区器不能满足需求,还可以继承org.apache.spark.Partitioner自定义分区器。
# 6.1 HashPartitoner
HashPartitioner 分区的原理:对于给定的 Key,计算其 hashCode,并除以分区的个数取余,如果余数小于 0,则用余数+分区的个数(否则加 0),最后返回的值就是这个 key 所属的分区 ID。
# 6.2 RangePartitioner
HashPartitioner 在极端情况下可能导致数据分区不均匀。RangePartitioner 刚好可以解决这个问题,它的原理是将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
# 6.3 自定义分区器
要实现自定义的分区器,需要继承org.apache.spark.Partitioner类并实现下面三个方法:
- numPartitions: Int,返回创建出来的分区数。
- getPartition(key: Any): Int,返回给定键的分区编号(0 到 numPartitions-1)。
- equals():判断相等性的标准方法。Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。