Hive DQL
DQL 全称 Data Query Language,即数据查询语言。从 Hive 的定位来讲,查询操作才是它最本质也是最核心的功能。
# select
语法:
[WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available starting with Hive 0.13.0)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
2
3
4
5
6
7
8
9
10
说明:
- WITH 子句和标准 SQL 中的 WITH 使用是一样的,就是将一个查询的结果起了一个别名(临时变量)方便再后面的查询中使用。
- SELECT 子句和标准 SQL 中的 SELECT 也没有区别。
- FROM 子句指定查询的输入,它可以是普通物理表,视图,join 查询结果或子查询结果。
- WHERE 子句指定查询条件。
- GROUP 子句指定分组条件。如果使用 GROUP BY 分组,则 select 后面只能写分组的字段或者聚合函数。
- HAVING 子句的优势在于 WHERE 关键字无法与聚合函数一起使用。HAVING 子句可以让我们筛选分组后的各组数据,并且可以在 Having 中使用聚合函数,因为此时 where,group by 已经执行结束,结果集已经确定。
- ORDER 语法类似于 SQL 语言中的 ORDER BY 语法。会对输出的结果进行全局排序,因此底层使用 MapReduce 引擎执行的时候,只会有一个 reduce task 执行。也因此,如果输出的行数太大,会导致需要很长的时间才能完成全局排序。默认排序顺序为升序(ASC),也可以指定为 DESC 降序。在 Hive 2.1.0 和更高版本中,支持在“ order by”子句中为每个列指定 null 类型结果排序顺序。ASC 顺序的默认空排序顺序为 NULLS FIRST,而 DESC 顺序的默认空排序顺序为 NULLS LAST。
- CLUSTER 子句可以指定根据后面的字段将数据分组,每组内再根据这个字段正序排序(不允许指定排序规则),概况起来就是:根据同一个字段,分且排序。分组的规则为 hash 散列。hash_func(col_name) % reduce_task_nums 分为几组取决于 reduce_task 的个数。
- CLUSTER 的功能是分且排序(同一个字段),那么 DISTRIBUTE BY + SORT BY 就相当于把 cluster by 的功能一分为二:DISTRIBUTE BY 负责分,SORT BY 负责分组内排序,并且可以是不同的字段。如果 DISTRIBUTE BY +SORT BY 的字段一样,可以得出下列结论:CLUSTER BY = DISTRIBUTE BY + SORT BY(字段一样)。
- LIMIT 子句可用于约束 SELECT 语句返回的行数。LIMIT 接受一个或两个数字参数,这两个参数都必须是非负整数常量。第一个参数指定要返回的第一行的偏移量(从 Hive 2.0.0 开始),第二个参数指定要返回的最大行数。当给出单个参数时,它代表最大行数,并且偏移量默认为 0。
重点
- ORDER BY 会对输入做全局排序,因此只有一个 reducer,会导致当输入规模较 大时,需要较长的计算时间。
- SORT BY 不是全局排序,其在数据进入 reducer 前完成排序。因此,如果用 SORT BY 进行排序,并且设置 mapred.reduce.tasks > 1,则 SORT BY 只保证每个 reducer 的输出有序,不保证全局有序。
- DISTRIBUTE BY(字段)根据指定的字段将数据分到不同的 reducer,且分发算法是 hash 散列。
- CLUSTER BY(字段) 除了具有 DISTRIBUTE BY 的功能外,还会对该字段进行排序。因此,如果分桶和 sort 字段是同一个时,此时,CLUSTER BY = DISTRIBUTE BY + SORT BY。
例:
-- 省略from子句的查询
select 8 * 888;
select current_date;
-- 大家最熟悉的
select * from student;
-- 指定列名
select id, name, age from student;
-- 统计
select count(*) from student;
-- 按列统计。count(colname) 按字段进行count,不统计NULL
select count(name) from student;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# union
UNION 用于将多个 SELECT 语句的结果组合成一个结果集,官方文档 (opens new window)语法为:
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...
说明:
- 1.2.0 之前的 Hive 版本仅支持 UNION ALL 语法,不会消除重复行。
- 使用 DISTINCT 可以删除重复行,如果不明确指定,默认的规则就是 DISTINCT,删除重复行。
- 每个 select_statement 返回的列的数量和名称必须相同。
- 每个 select_statement 返回的字段位置从左往右需要一一对应, 否则会出现字段错位的情况。
例:
-- 默认删除重复行
select name, age from student1
union
select name, age from student2;
-- 指定 distinct 关键字,效果和上面一样
select name, age from student1
union distinct
select name, age from student2;
-- 使用 all 关键字会保留重复行
select name, age from student1
union all
select name, age from student2;
-- 以下查询会出现字段错位
select name, age from student1
union all
select age, name from student2;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# join
如果你已经开始学习 Hive 了,那我相信你对 join 一定不会陌生(之前的 SQL 基础课中肯定会涉及到),所以这里不罗列 join 的概念以及使用场景,直接切入主题。
语法:
join_table:
table_reference [INNER] JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON expression
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- table_reference:是 join 查询中使用的表名,也可以是子查询别名(查询结果当成表参与 join)。
- table_factor:与 table_reference 相同,是联接查询中使用的表名,也可以是子查询别名。
- join_condition:join 查询关联的条件, 如果在两个以上的表上需要连接,则使用 AND 关键字。
从上面的语法中可以看到 Hive 中的 jon 分为 6 种类型:
- inner join。内连接,inner 关键字可以省略。
- outer join。外连接,又分为 left、right 和 full 三种,其中 outer 关键字可以省略。
- left outer join
- right outer join
- full outer join
- left semi join。左半开连接。
- cross join。笛卡尔积,慎用。
提示
在 Spark SQL 中还有一个名为 left anti 的 join 操作,和 left semi 对应,感兴趣的可以查一下。
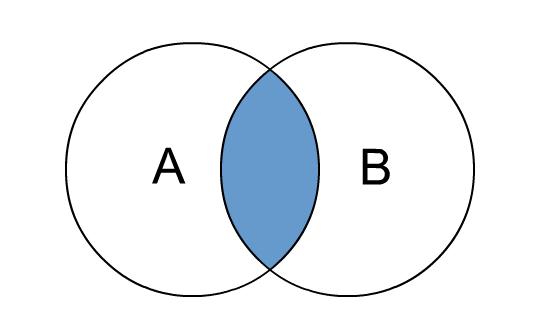
# inner join
inner join和join是等价的,只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。
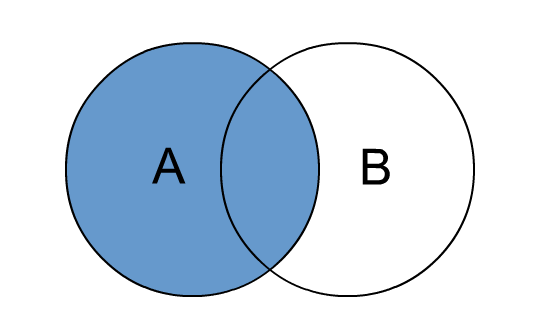
# left join
left outer join和left join是等价的,join 时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示 null 返回。
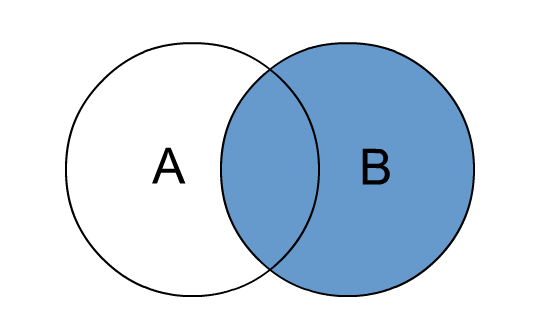
# right join
right outer join和right join是等价的,join 时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示 null 返回。
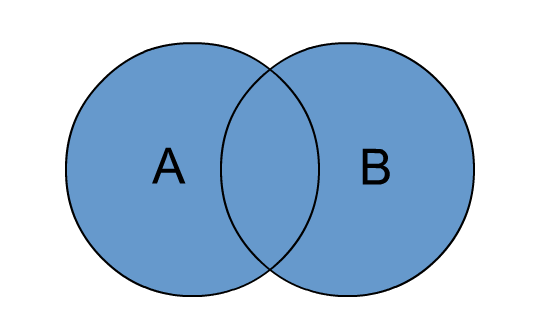
# full join
full outer join 和 full join 是等价的。包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行 在功能上,它等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
# left semi join
left semi join会返回左边表的结果,从效果上来讲是和inner join一样的,唯一不同的是left semi join之后只会返回左边表的字段,而inner join可以自己决定返回左右表的哪几个字段。假设我们想 A 和 B 两个表 join 之后只保留左边的字段,右边字段不实用的话就可以用left semi join。
# cross join
cross join将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。慎用,大数据集会导致集群崩溃。
说明:
join 操作在 where 条件之前执行。
允许使用复杂的联接表达式。
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
2
3
- 同一查询中可以连接 2 个以上的表。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 如果每个表在联接子句中使用相同的列,则 Hive 将多个表上的联接转换为单个 MR 作业。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
--会转换为两个MR作业,因为在第一个连接条件中使用了b中的key1列,而在第二个连接条件中使用了b中的key2列。第一个map / reduce作业将a与b联接在一起,然后将结果与c联接到第二个map / reduce作业中。
2
3
4
- join 时的最后一个表会通过 reducer 流式传输,并在其中缓冲之前的其他表,因此,将大表放置在最后有助于减少 reducer 阶段缓存数据所需要的内存。
-- 由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行,并且表a和b的键的特定值的值被缓冲在reducer的内存中。然后,对于从c中检索的每一行,将使用缓冲的行来计算联接。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
-- 计算涉及两个MR作业。其中的第一个将a与b连接起来,并缓冲a的值,同时在reducer中流式传输b的值。在第二个MR作业中,将缓冲第一个连接的结果,同时将c的值通过reducer流式传输。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
2
3
4
5
- 在 join 的时候,可以通过语法 STREAMTABLE 提示指定要流式传输的表。如果省略 STREAMTABLE 提示,则 Hive 将流式传输最右边的表。
-- a,b,c三个表都在一个MR作业中联接,并且表b和c的键的特定值的值被缓冲在reducer的内存中。然后,对于从a中检索到的每一行,将使用缓冲的行来计算联接。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
2
- 如果除一个要连接的表之外的所有表都很小,则可以将其作为仅 map 作业执行。
-- 不需要reducer。对于A的每个Mapper,B都会被完全读取。限制是不能执行FULL / RIGHT OUTER JOIN b。
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key
2
更多细节可以参考官方文档 (opens new window)。