JVM 架构
# 一、JVM 简述
JVM 即 Java Virtual Machine,Java 虚拟机运行在操作系统之上,是一台执行 Java 字节码的虚拟计算机,拥有独立的运行机制。它的作用就是运行二进制字节码(装载字节码并解释为对应操作系统的机器指令),其运行的 Java 字节码也未必是 Java 语言编译产生的。
另外,从下图可以看出,JVM 和硬件没有直接交互。
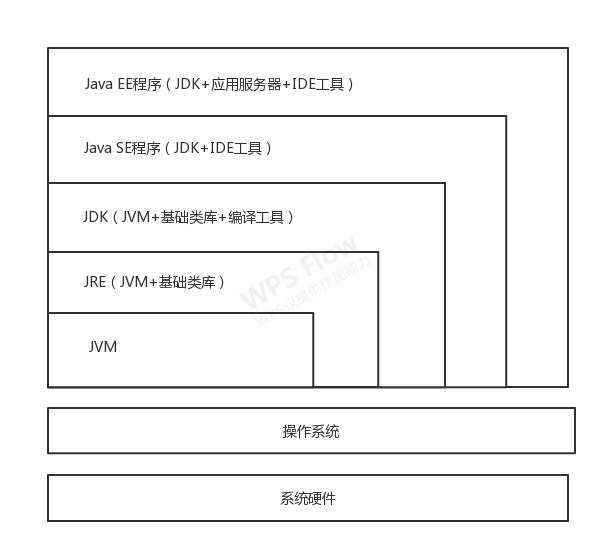
自从 1996 年初 Sun 发布的 JDK1.0 中包含的 Sun Classic 虚拟机到今天,曾出现过许许多多的虚拟机版本,它们各有特色、万家争鸣。包括但不限于:
- Sun Classic/Exact VM
- HotSpot VM
- Mobile/Embedded VM
- BEA JRockit/IBM J9 VM
- BEA Liquid VM/Azul VM
- Apache Harmony/Google Android Dalvik VM
- Microsoft JVM
- KVM
- JCVM
- Squawk VM
- JavaInJava
- Maxine VM
- Jikes RVM
- IKVM.NET
在众多虚拟机版本中,HotSpot VM 目前是使用范围最广的,它是 Sun/Oracle JDK 和 Open JDK 中默认的 Java 虚拟机。
# 二、JVM 架构概览
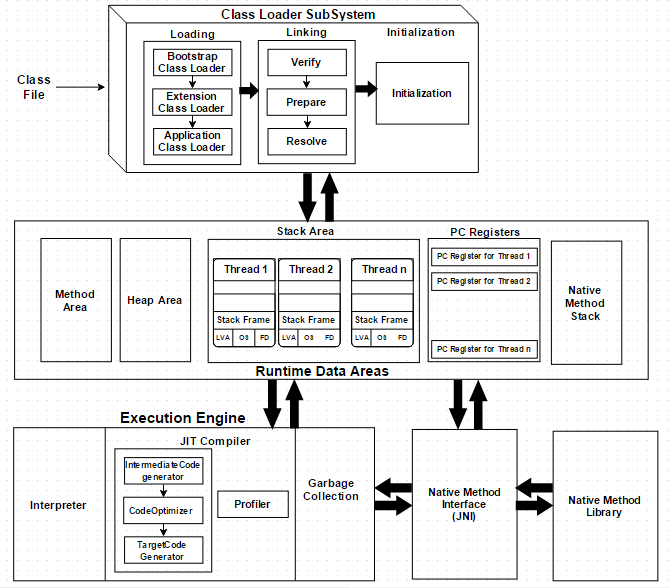
如上图所示,JVM 总共包含三个子系统:
- 类加载子系统(Class Loader SubSystem)
- 运行时数据区(Runtime Data Areas)
- 执行引擎(Execution Engine)
# 2.1 类加载器子系统
类加载器子系统负责加载 class 文件,class 文件在文件开头有特定的文件标识,将 class 文件字节码内容加载到内存中,并将这些内容转换成方法区中的运行时数据结构,并且类加载器只负责 class 文件的加载,至于其是否可以运行则有执行引擎决定。
加载的类信息存放于方法区中(方法区除了类信息之外,还会存放运行时常量池以及其它信息)。
# 2.1.1 类加载器分类
虚拟机自带的类加载器:
- 启动类加载器(Bootstrap Class Loader)
- 扩展类加载器(Extension Class Loader)
- 应用类加器器(Application Class Loader)
用户自定义类加载器:java.lang.ClassLoader 的子类,用户可以定制类的加载方式。
# 2.1.2 双亲委派机制
当一个类加载器收到了类加载请求,首先不会尝试自己去加载此类,而是将其请求委派给父类去完成,父类也会将其尝试委派给自己的父类去完成,因此所有的加载请求都最终会传送到启动类加载器中。只有当父类加载器反馈自己无法完成这个请求的时候,也就是在自己的加载路径下没有找到所需要的 Class,子类加载器才会尝试自己去加载。
# 2.2 运行时数据区
运行时数据区是 JVM 最核心的部分,也是面试考察最多的,会开启专门的章节详述。
# 2.3 执行引擎
分配给运行时数据区的字节码将由执行引擎执行,执行引擎读取字节码并一一执行。执行引擎由 3 部分组成:解释器(Interpret)、即时编译器(JIT Compiler)和垃圾回收器(Garbage Collector)。
# 2.3.1 解释器
解释器读取字节码并一一执行。解释器的缺点是当一个方法被多次调用时,每次都需要解释。
# 2.3.2 即时编译器
即时编译器消除了解释器的缺点(一个方法调用多次,每次都需要解释),执行引擎将使用解释器进行解释转换,但是当它发现重复的代码时,会使用即时编译器来编译整个字节码并将其更改为 native 代码。该本机代码将直接用于提高系统性能的重复方法调用。
- 中间代码生成器(Intermediate Code generator):生成中间代码。
- 代码优化器(Code Optimizer):负责优化上面生成的中间代码。
- 目标代码生成器(Target Code Generator):目标代码生成器负责生成机器代码/native 代码。
- 探查器(Profiler):探查器是一个特殊的组件,它负责寻找识别该方法是否被多次调用。
# 2.3.3 垃圾回收器
垃圾收集器(Garbage Collector)是执行引擎的一部分,它收集/删除未引用的对象。垃圾回收可以通过调用System.gc()来触发,但不能保证执行。JVM 的垃圾收集器只收集那些由 new 关键字创建的对象。因此,如果创建了任何没有 new 的对象,可以使用 finalize 方法执行清理。
# 参考资料
JVM 系列总结主要参考以下资料:
- 周志明《深入理解 JVM 虚拟机第三版》
- 宋红康《详解 Java 虚拟机》
- GitChat《JVM 核心技术 32 讲》
- Java Virtual Machine Architecture In Java (opens new window)