Spark RDD 源码分析
# 1. RDD 概述
# 1.1 RDD 概念
RDD(Resilient Distributed Dataset)是 Spark 中绕不开的话题。它表示了 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合,所有的运算以及操作都建立在 RDD 数据结构的基础之上。
RDD 提供了一个抽象的数据模型,不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API(map/reduec/filter/groupBy 等)。
# 1.2 RDD 五大特征
Spark 源码中描述了 RDD 的五大特征:

- 一组 Partition。Partition 是 RDD 的基本组成单位,每个 Partition 都会被一个 Task 处理,Partition 数量决定任务并行度。用户可以在创建 RDD 的时候指定分区数,如果没有指定则会采用默认值。
- 一个计算每个分区的函数。RDD 的计算是以 Partition 为单位的,计算函数会作用到每个分区上。
- RDD 之间的依赖关系。RDD 的每次转换都会生成一个新的 RDD,所以 RDD 之间会形成一个前后依赖关系。在部分分区数据丢失或 Task 执行失败以后可以通过依赖关系重新计算该分区的数据,而不是重新计算所有分区。
- 一个针对 Key-Value 型 RDD 的分区器(可选的)。对于 Key-Value 型的 RDD 会有一个分区器,非 Key-Value 型的 RDD 分区器是 None。Spark 中内置的有 HashPartitioner 和 RangePartitioner。
- 一个列表,存储存取每个 Partition 的优先位置(可选的)。对于一个 HDFS 文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照"移动数据不如移动计算"的理念,Spark 在进行任务调度的时候,会尽可能选择那些存有数据的 worker 节点来进行任务计算。
所有的调度和计算都是基于以上属性进行的,Spark 用户可以在org.apache.spark.rdd.RDD类的基础上实现自己的 RDD。可以在Spark 论文 (opens new window)看关于 RDD 具体的设计。
# 2. RDD 源码
抽象类 org.apache.spark.rdd.RDD 定义了 RDD 的规范,在 3.0.0 版本中,它有 70 多个实现类(不包括匿名实现类):
点击查看
- BadRDD
- BaseRRDD
- BinaryFileRDD
- BlockRDD
- CartesianRDD
- CheckpointRDD
- CoGroupedRDD
- CoalescedRDD
- ContinuousCoalesceRDD
- ContinuousDataSourceRDD
- ContinuousShuffleReadRDD
- ContinuousWriteRDD
- CustomShuffledRDD
- CyclicalDependencyRDD
- DataSourceRDD
- EdgeRDD
- EdgeRDDImpl
- EmptyRDD
- EmptyRDDWithPartitions
- FatPairRDD
- FatRDD
- FetchFailureHidingRDD
- FetchFailureThrowingRDD
- FileScanRDD
- HadoopMapPartitionsWithSplitRDD
- HadoopRDD
- JDBCRDD
- JdbcRDD
- KafkaRDD
- KafkaSourceRDD
- LocalCheckpointRDD
- LocationPrefRDD
- MapPartitionsRDD
- MapWithStateRDD
- MockRDD
- MockRDDWithLocalityPrefs
- MyCheckpointRDD
- MyCoolRDD
- MyRDD
- NewHadoopMapPartitionsWithSplitRDD
- NewHadoopRDD
- PairwiseRDD
- PairwiseRRDD
- ParallelCollectionRDD
- PartitionPruningRDD
- PartitionerAwareUnionRDD
- PartitionwiseSampledRDD
- PipedRDD
- PythonRDD
- RRDD
- RandomRDD
- RandomVectorRDD
- ReliableCheckpointRDD
- SQLExecutionRDD
- ShuffledRDD
- ShuffledRowRDD
- SlidingRDD
- StateStoreAwareZipPartitionsRDD
- StateStoreRDD
- StringRRDD
- SubtractedRDD
- UnionRDD
- UnsafeCartesianRDD
- VertexRDD
- VertexRDDImpl
- WholeTextFileRDD
- WriteAheadLogBackedBlockRDD
- ZippedPartitionsBaseRDD
- ZippedPartitionsRDD2
- ZippedPartitionsRDD3
- ZippedPartitionsRDD4
- ZippedWithIndexRDD
org.apache.spark.rdd.RDD的源码内容也比较多,有将近 1900 行,总体上可以分为三部分去看:
- 属性部分。
- 一些需要子类重写的方法。
- 普通方法。这部分方法又可以分为两块:算子(Transform 算子、Action 算子)和其它通用方法。
# 2.1 属性
- _sc: SparkContext。即 SparkContext。
- deps: Seq[Dependency[_]。依赖列表,用来存储当前 RDD 的依赖。
- partitioner: Option[Partitioner]。当前 RDD 的分区计算器,默认为
None,需要子类去实现。 - id: Int。当前 RDD 的 id,该 id 在当前 SparkContext 中唯一。实际上调用了 SparkContext 的
newRddId()方法。 - name: String。RDD 的名称。
- dependencies_ : Seq[Dependency[_]]。与 deps 相同,只是 deps 不可以被序列化,而 dependencies_可以序列化。
- partitions_ : Array[Partition]。存储当前 RDD 的所有分区的数组。
- storageLevel: StorageLevel。当前 RDD 的存储级别。可选项有:
- NONE
- DISK_ONLY
- DISK_ONLY_2
- MEMORY_ONLY
- MEMORY_ONLY_2
- MEMORY_ONLY_SER
- MEMORY_ONLY_SER_2
- MEMORY_AND_DISK
- MEMORY_AND_DISK_2
- MEMORY_AND_DISK_SER
- MEMORY_AND_DISK_SER_2
- OFF_HEAP
- creationSite。创建当前 RDD 的用户代码,实际上调用了 SparkContext 的
getCallSite()方法。 - scope: Option[RDDOperationScope]。当前 RDD 操作的作用域。
- checkpointData: Option[RDDCheckpointData[T]]。当前 RDD 的检查点数据。
- checkpointAllMarkedAncestors: Boolean。是否对所有标记了需要保存检查点的祖先保存检查点。
- doCheckpointCalled: Boolean。是否已经调用了 doCheckpoint 方法设置检查点,用于阻止多次对 RDD 设置检查点。
- isBarrier_ : Boolean。从性能考虑,缓存该值以避免在长 RDD 链上重复执行
isBarrier()方法。 - outputDeterministicLevel: DeterministicLevel.Value。返回此 RDD 输出的确定性级别。可选项有:
- DETERMINATE
- UNORDERED
- INDETERMINATE
- stateLock = new Serializable {}。同步代码块用到的锁对象。
# 2.2 需子类重写的方法
org.apache.spark.rdd.RDD源码中的第二部分是几个需要子类实现的方法。
// 真正执行数据计算的地方,对 RDD 的分区进行计算。
def compute(split: Partition, context: TaskContext): Iterator[T]
// 获取当前 RDD 的所有分区
protected def getPartitions: Array[Partition]
// 获取当前 RDD 的所有依赖
protected def getDependencies: Seq[Dependency[_]] = deps
// 获取某一个分区的优先位置
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
2
3
4
5
6
7
8
9
10
11
12
# 2.3 普通方法
除了上述的两部分代码之外,剩下的部分就是一些普通方法。这部分代码中又可以分为两部分:
- 算子(Transform 算子、Action 算子)
- 其它通用方法
其中算子的代码是占比最多的。
# 3. RDD 依赖
RDD 的容错机制是通过将 RDD 间转移操作构建成有向无环图来实现的。从抽象的角度看,RDD 间存在着血统继承关系,其本质上是 RDD 之间的依赖(Dependency)关系。RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(shuffle dependency)。
# 3.1 窄依赖
窄依赖中每个父 RDD 的 Partition 最多被一个子 RDD 的一个 Partition 使用。
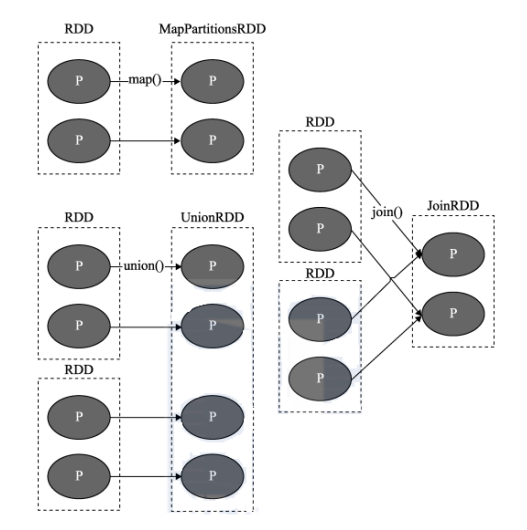
# 3.2 宽依赖
宽依赖中多个子 RDD 的 Partition 会依赖同一个父 RDD 对的 Partition,会引起 Shuffle。
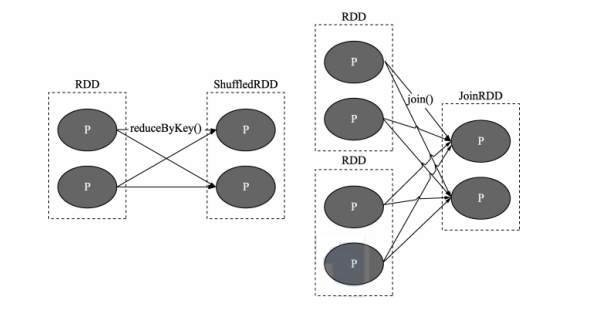
提示
关于窄依赖和宽依赖的概念容易混淆,其实窄依赖就是独生子女,宽依赖就是非独生子女。这样就好记多了。
# 3.3 Dependency 源码
Spark 使用抽象类Dependency来表示 RDD 之间的依赖关系,它有两个子类分别是NarrowDependency和ShuffleDependency。NarrowDependency有两个子类,分别是OneToOneDependency和RangeDependency。
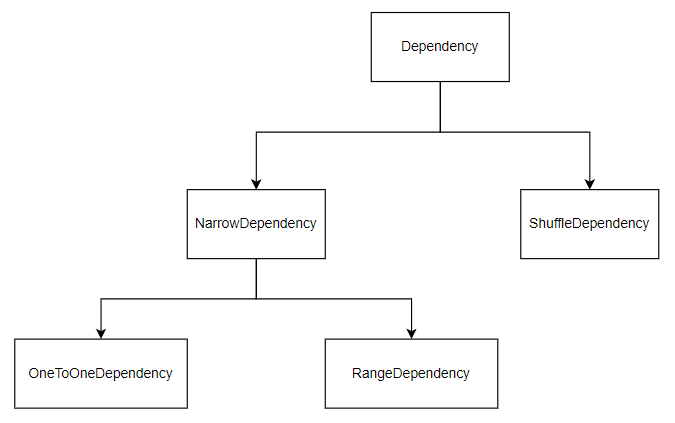
源码如下:
abstract class Dependency[T] extends Serializable {
// 返回当前依赖的 RDD
def rdd: RDD[T]
}
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
// 获取父 Partition 序列
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
// 表示子 RDD 的 Partition 与父 Partition 相同
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner, // 分区计算器
val serializer: Serializer = SparkEnv.get.serializer, // 序列化组件
val keyOrdering: Option[Ordering[K]] = None, // K 排序的实现类
val aggregator: Option[Aggregator[K, V, C]] = None, // 对 map 任务的输出进行聚合的聚合器
val mapSideCombine: Boolean = false, // 是否在 map 端进行合并
val shuffleWriterProcessor: ShuffleWriteProcessor = new ShuffleWriteProcessor // 控制ShuffleMapTask中的写入行为的处理器
) extends Dependency[Product2[K, V]] {
if (mapSideCombine) {
require(aggregator.isDefined, "Map-side combine without Aggregator specified!")
}
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
private[spark] val combinerClassName: Option[String] = Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
_rdd.sparkContext.shuffleDriverComponents.registerShuffle(shuffleId)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56