Hive 客户端的使用
# Hive 客户端概述
Hive 发展至今,总共历经了两代客户端工具。
第一代客户端:/bin/hive, 是一个 Shell Util。主要功能:一是可用于以交互或批处理模式运行 Hive 查询;二是用于 Hive 相关服务的启动,比如 Metastore 服务。已经过时,官方不推荐使用。
第二代客户端:/bin/beeline,是一个 JDBC 客户端,是官方强烈推荐使用的 Hive 命令行工具,和第一代客户端相比,性能加强安全性提高。
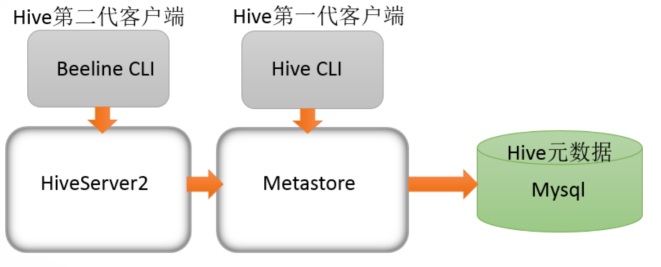
Beeline Shell 在嵌入式模式和远程模式下均可工作。在嵌入式模式下,它运行嵌入式 Hive(类似于 Hive Client),而远程模式下 beeline 通过 Thrift 连接到单独的 hiveserver2 服务上,这也是官方推荐在生产环境中使用的模式。
那么问题来了,hiveserver2 是什么?hiveserver1 哪里去了?
hiveserver、hiveserver2 都是 Hive 自带的两种服务,允许客户端在不启动 Cli 的情况下对 Hive 中的数据进行操作,且两个都允许远程客户端使用多种编程语言如 java,python 等向 hive 提交请求,取回结果。但是,hiveserver 不能处理多于一个客户端的并发请求。因此在 Hive-0.11.0 版本中重写了 hiveserver 代码得到了 hiveserver2,进而解决了该问题。hiveserver 已经被废弃。hiveserver2 支持多客户端的并发和身份认证,旨在为开放 API 客户端如 JDBC、ODBC 提供更好的支持。
hiveserver2 通过 Metastore 服务读写元数据。所以在远程模式下,启动 hiveserver2 之前必须先首先启动 Metastore 服务。程模式下,Beeline 客户端只能通过 hiveserver2 服务访问 Hive。而 Hive Client 是通过 Metastore 服务访问的。具体关系如下:
在 Hive 的 bin 目录下执行ll 命令可以看到hive、beeline以及hiveserver2。
# 第一代客户端使用
在 Hive 安装目录下直接执行bin/hive就可以使用第一代客户端工具,不需要任何配置。执行bin/hive -help可以查看相关参数:
$ /opt/module/hive
bin/hive -help
readlink: illegal option -- f
usage: readlink [-n] [file ...]
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 重点参数:
-e:不进入 hive 交互窗口,执行 sql 语句
hive -e "select * from users"
-f:执行脚本中 sql 语句
# 创建文件hqlfile1.sql,内容:select * from users
# 执行文件中的SQL语句
hive -f hqlfile1.sql
# 执行文件中的SQL语句,将结果写入文件
hive -f hqlfile1.sql >> result1.log
2
3
4
5
6
# 其它命令操作
- 在 Hive Cli 命令窗口中如何查看 hdfs 文件系统
hive> dfs -ls /;
- 在 Hive Cli 命令窗口中如何查看本地文件系统
hive> ! ls /opt/module/datas;
- 查看在 Hive 中输入的所有历史命令
进入到当前用户家目录,执行
cat .hivehistory。
cd ~
cat .hivehistory
2
3
# 第二代客户端使用
- 启动 hiveserver2 服务
bin/hiveserver2
- 启动 beelin 并连接 hiveserver2
$ bin/beeline
readlink: illegal option -- f
usage: readlink [-n] [file ...]
Beeline version 1.2.2 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: test
Enter password for jdbc:hive2://localhost:10000: ****
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
+----------------+--+
1 rows selected (0.11 seconds)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
主机名以及用户名按需修改。