Spark Shuffle
# 一、Spark Shuffle 历史演进
在 Spark 中,每当遇到一个宽依赖就会产生一个 Shuffle,也就是父 RDD 中的每个 Partition 被子 RDD 中的多个 Partition 使用的时候就会产生 Shuffle(可以理解为非独生子女)。
Spark Shuffle 历史演进时间线:
- Spark 0.8 及以前 Hash Based Shuffle。
- Spark 0.8.1 为 Hash Based Shuffle 引入 File Consolidation 机制。
- Spark 0.9 引入 ExternalAppendOnlyMap。
- Spark 1.1 引入 Sort Based Shuffle,但默认仍为 Hash Based Shuffle。
- Spark 1.2 默认的 Shuffle 方式改为 Sort Based Shuffle。
- Spark 1.4 引入 Tungsten-Sort Based Shuffle。
- Spark 1.6 Tungsten-Sort Based Shuffle 并入 Sort Based Shuffle,如果检测到满足 Tungsten-Sort Based Shuffle 条件会自动采用 Tungsten-Sort Based Shuffle,否则采用 Sort Shuffle。
- Spark 2.0 Hash Based Shuffle 退出历史舞台。
Spark Shuffle 主要经历了以下三个阶段:
- Hash Based Shuffle
- Sort Based Shuffle
- Tungsten-Sort Based Shuffle
# 1.1 Hash Based Shuffle
# 1.1.1 未优化的 Hash Based Shuffle
Spark 中最早出现的就是 Hash Based Shuffle,它的主要原理是:
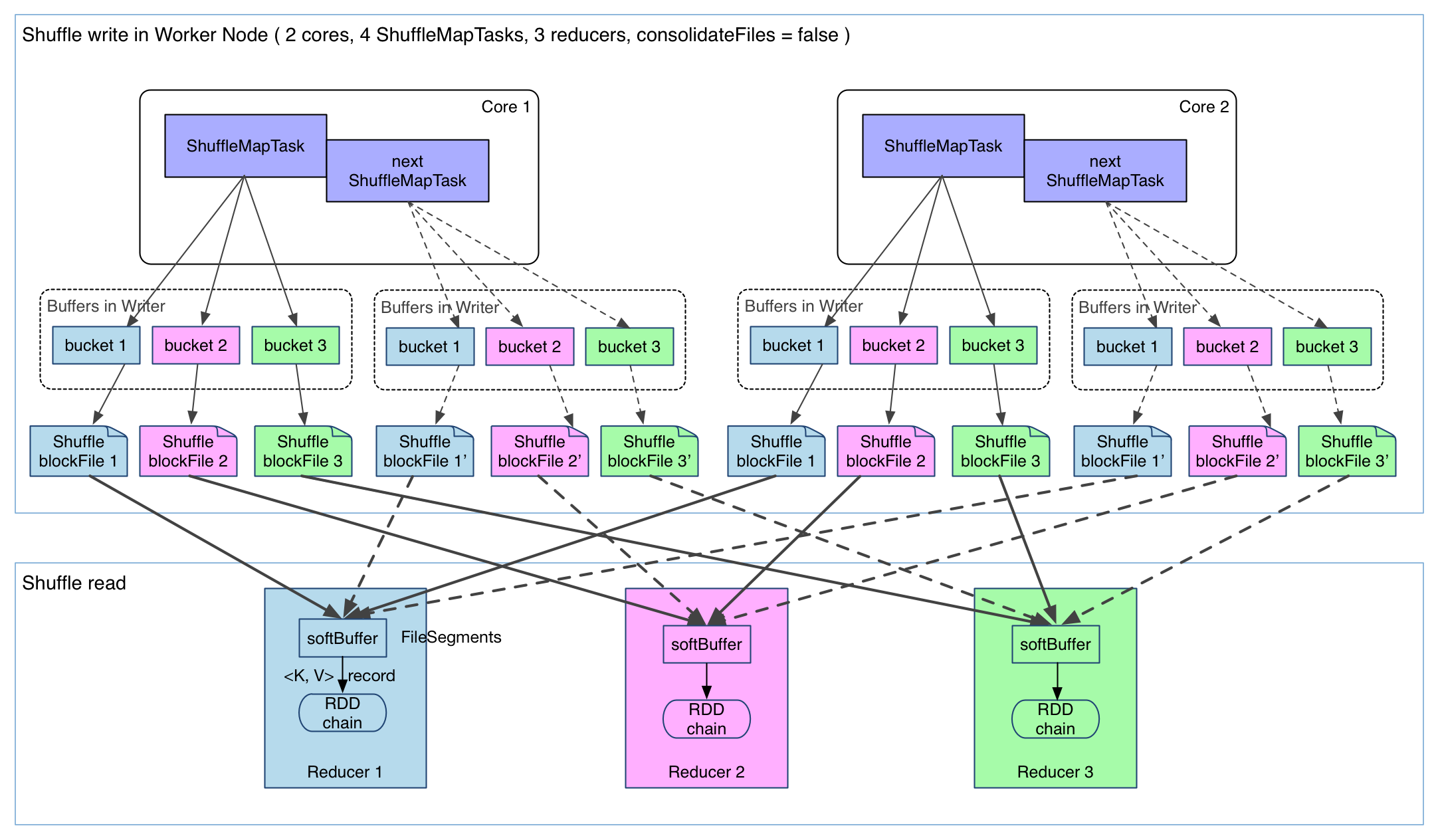
- map 任务会为每一个 reduce 任务创建一个 bucket。假设有 M 个 map 任务,R 个 reduce 任务,则 map 阶段总共会创建 M * R 个 bucket。
- map 任务会将产生的中间结果按照 partition 写入到不同的 bucket 中。
- reduce 任务从本地或者远端的 map 任务所在的 BlockManager 获取相应的 bucket 作为输入。
但是 Hash Based Shuffle 存在一些很明显的弊端:
- map 任务的中间结果首先写入内存,然后才写入磁盘。当一个节点上的 map 任务输出结果很大时,很容易导致 OOM。
- 如果 map 任务和 reduce 都比较多的话,那么在 map 阶段会创建大量的 bucket,如果 Shuffle 很频繁的话,磁盘 IO 会成为性能瓶颈。
# 1.1.2 优化的 Hash Based Shuffle
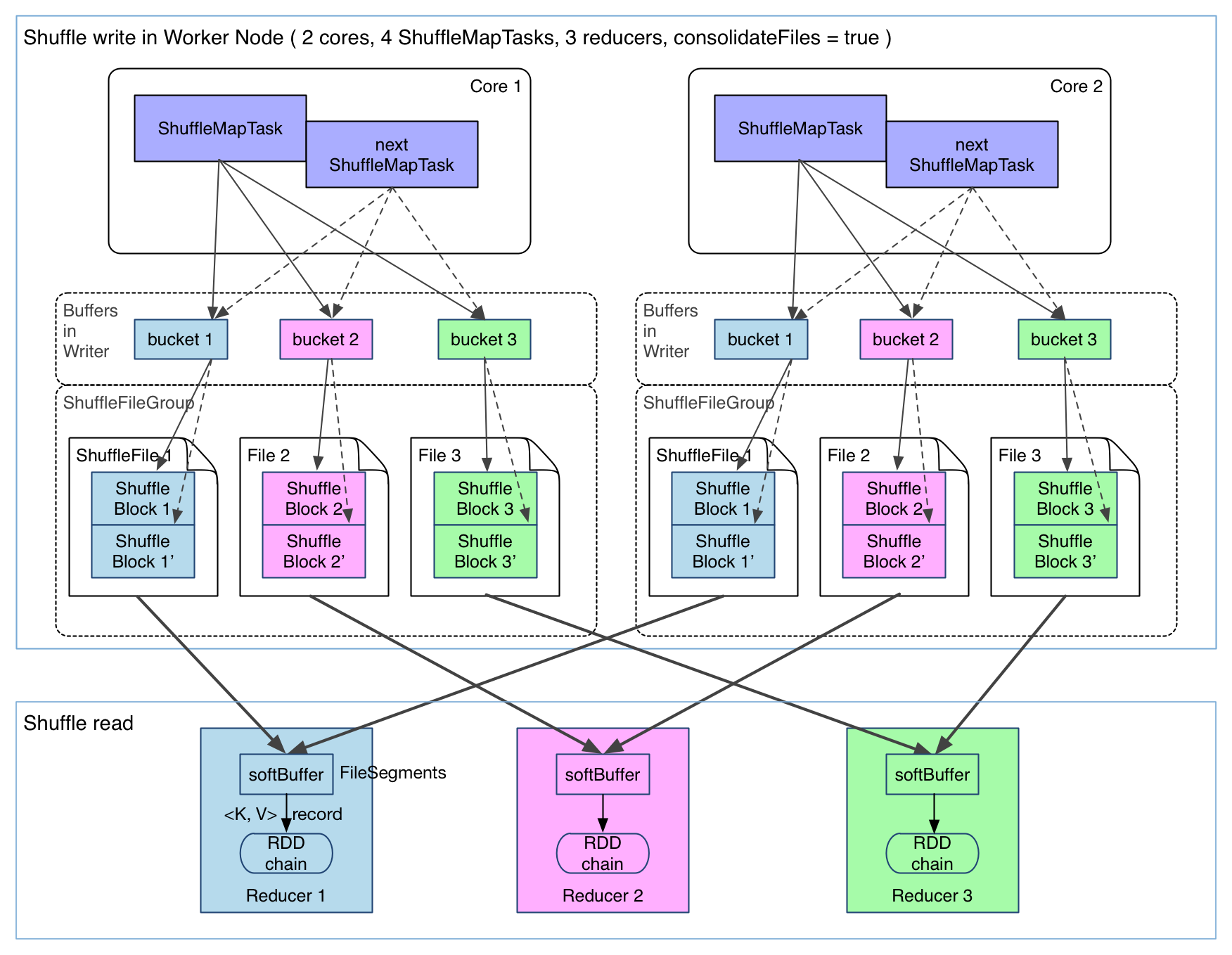
在 Spark 0.8.1 版本中引入了 File Consolidation 机制。即在同一个 Core 中,所有的 map 任务将相同 partition 的输出合并到同一个文件中,这样的话就可以大大缓解数据本身不大但是 bucket 数量多造成的 IO 性能瓶颈。参数spark.shuffle.consolidateFiles=true用来配置是否开启 File Consolidation 机制。
在 Spark 0.9 版本中引入了 ExternalAppendOnlyMap,即在 combine 的时候,可以将数据溢写到磁盘,然后通过堆排序 Merge。
# 1.2 Sort Based Shuffle
从 Spark 1.1 版本开始引入了 Sort Based Shuffle,在 Sort Based Shuffle 中,map 阶段的每个 Task 不会为 reduce 阶段的每个 Task 创建单独的文件,而是将所有对结果写入同一个文件。该文件中的记录首先是按照 Partition Id 排序,每个 Partition 内部再按照 Key 进行排序,map Task 运行期间会顺序写每个 Partition 的数据,同时生成一个索引文件记录每个 Partition 的大小和偏移量。
在 reduce 阶段,Task 拉取数据做 combine 时不再是采用 HashMap,而是采用 ExternalAppendOnlyMap,该数据结构在做 combine 时,如果内存不足,会刷写磁盘,很大程度上保证了系统的稳定性,避免了大数据情况下的 OOM。
# 1.3 Tungsten-Sort Based Shuffle
Spark Tungsten 是从 1.5.0 开始由 Databricks 提出的 Spark 性能优化计划,其中包括了对于 Shuffle 的部分优化。由于使用了堆外内存,而它基于 JDK Sun Unsafe API,故 Tungsten-Sort Based Shuffle 也被称为 Unsafe Shuffle。
关于 Tungsten 计划可以参考探索 Spark Tungsten 的秘密 (opens new window) 和 Spark Tungsten(钨):优化 Spark 核心执行引擎 (opens new window)。
它的做法是将数据记录用二进制的方式存储,直接在序列化的二进制数据上 Sort 而不是在 Java 对象上,这样一方面可以减少内存的使用和 GC 的开销,另一方面避免 Shuffle 过程中频繁的序列化以及反序列化。在排序过程中,它提供 cache-efficient sorter,使用一个 8 bytes 的指针,把排序转化成了一个指针数组的排序,极大的优化了排序性能。
但是使用 Tungsten-Sort Based Shuffle 有几个限制,Shuffle 阶段不能有 aggregate 操作,分区数不能超过一定大小(2^24-1,这是可编码的最大 Parition Id),所以像 reduceByKey 这类有 aggregate 操作的算子是不能使用 Tungsten-Sort Based Shuffle,它会退化采用 Sort Shuffle。
# 二、Shuffle 核心类
Shuffle 是一个非常复杂的过程,依赖于很多实现。核心类如下所示:
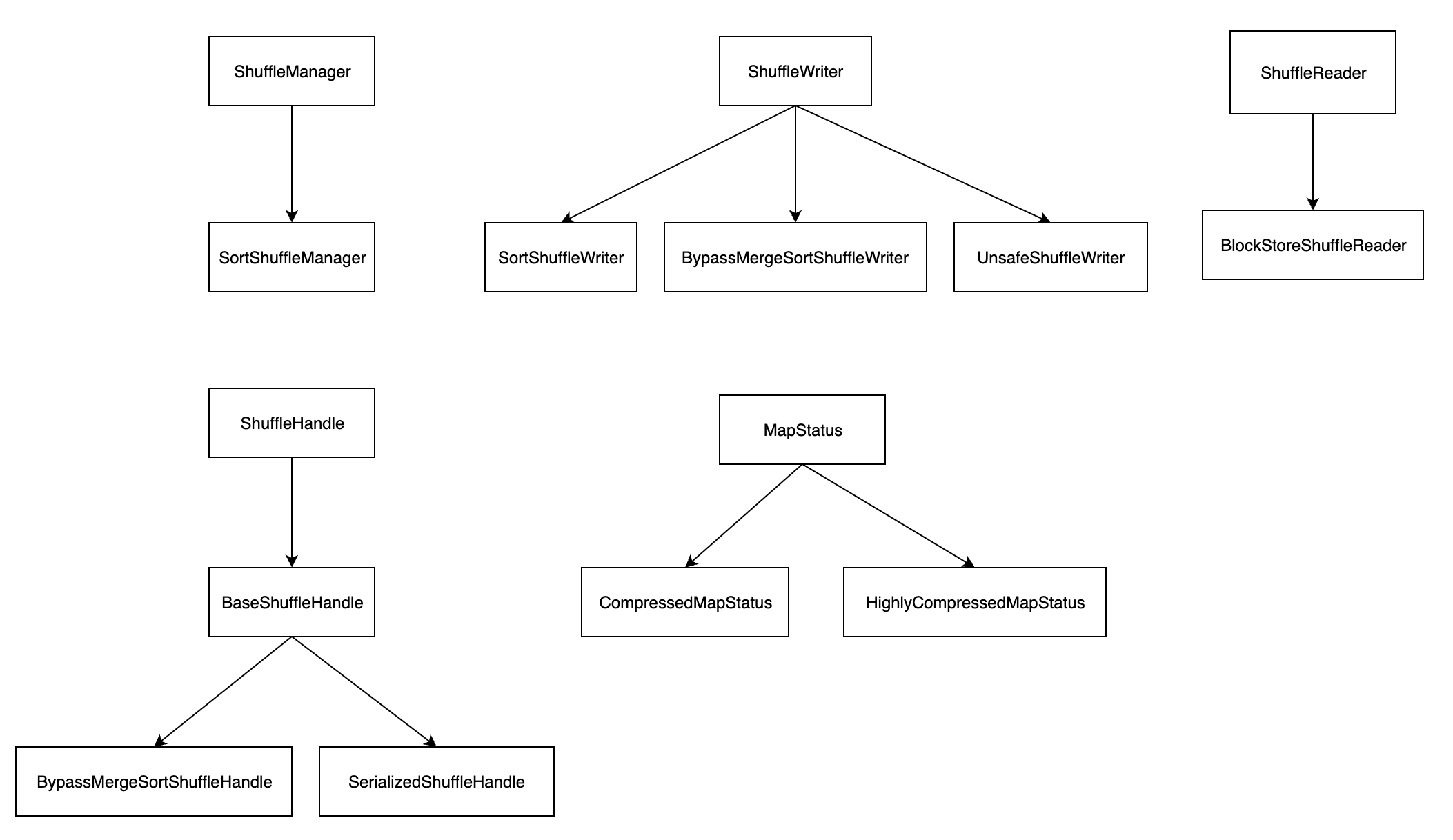
- ShuffleManager:ShuffleManager 是负责 Shuffle 过程的执行、计算、处理的组件,是一个可插拔式的接口。在 Spark 2.0 之后只有一个实现类 SortShuffleManager。在 Spark 2.0 之前还有一个 HashShuffleManager 实现类,但是由于性能太差,在 2.0 版本中移除了。
- ShuffleWriter:ShuffleWriter 是一个抽象类,定义了 map 任务将中间结果输出到磁盘上的规范。ShuffleWriter 有三个实现类:SortShuffleWriter、BypassMergeSortShuffleWriter 和 UnsafeShuffleWriter。
- ShuffleReader:ShuffleReader 是一个接口,用于 reduce 任务读取 map 的输出结果。ShuffleReader 只有一个实现类 BlockStoreShuffleReader。
- ShuffleHandle:ShuffleHandle 本身是一个抽象类,虽然有三个子类,但是三个子类都没有具体的实现,只是用来向 Task 传递信息。
- MapStatus:MapStatus 是一个接口,用来表示 ShuffleMapTask 返回给 TaskSchedule 的执行结果。一般使用 CompressedMapStatus,如果数据量大会使用 HighlyCompressedMapStatus,表示高度压缩。
# 参考
- https://zhuanlan.zhihu.com/p/67061627